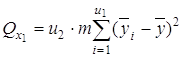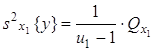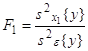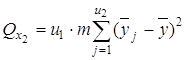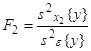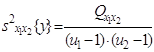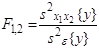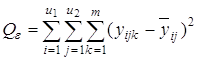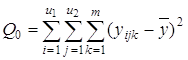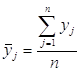|
Рефератыкосмонавтике административному праву хозяйственному праву устройствам экологическому праву криминалогия гражданский и землепользование обществознание |
Учебное пособие: Дисперсионный анализ при помощи системы MINITAB для WINDOWSУчебное пособие: Дисперсионный анализ при помощи системы MINITAB для WINDOWSМинистерство образования и науки Украины Севастопольский национальный технический университет
МЕТОДИЧЕСКИЕ УКАЗАНИЯк выполнению лабораторной работы № 3 и 4 ” Дисперсионный анализ при помощи системы MINITAB для WINDOWS “ по учебной дисциплине “Прикладная статистика”для студентов экономических специальностей всех форм обучения Севастополь 2008 Методические указания рассмотрены и утверждены на заседании кафедры менеджмента и экономико -математических методов протокол № “_____” от “______________” 2008г. Рецензент: доцент департамента учета и аудита Т.А.Мараховская 1. Цель работы Изучение возможностей дисперсионного анализа, для выявления зависимостей между экономическими показателями и получение практических навыков работы в системе MINITAB. Теоретические сведения 2.1. Дисперсионный анализ 2.1.1. Однофакторный дисперсионный анализ При проведении экономического анализа часто необходимо оценить влияние на целевую функцию y качественного фактора x . Таким фактором могут быть, например, партии сырья, отрасли промышленности, регионы и т.д. Пусть данные о влиянии некоторого качественного фактора на количественный в форме таблицы. Таблица 1.1. – влияние качественного фактора на исследуемый показатель
Модель зависимости значений
где По выборочным данным можно вычислить: 1)
среднее
2)
общее среднее
3) общую сумму квадратов отклонений Q0:
4) сумму квадратов, характеризующую влияние фактора x (отклонения между группами)
5) остаточную сумму квадратов, зависящую от ошибки e (отклонения внутри групп)
Тождество дисперсионного анализа имеет вид:
На основании вычисленных сумм квадратов вычисляются: 1)
оценка дисперсии
относительно общего среднего
где 2) оценка дисперсии «между группами», определяемыми уровнями xj:
где число степеней
свободы 3) выборочная оценка дисперсии «внутри групп», вычисляемая как средняя оценка по всем u группам:
с числом степеней свободы
Числа степеней свободы должны удовлетворять соотношению
Для того, чтобы сделать вывод о том, влияет ли на исследуемые показатели качественный фактор, сопоставляют дисперсию между группами с общей дисперсией. При этом выдвигают следующие гипотезы: H0: H1: Оценивание значимости влияния фактора x выполняется по F-критерию Фишера, для чего формируется следующее F-отношение:
Фактор x признается
незначимым, если соответствующее F-отношение оказывается меньше критического,
выбранного из таблиц для принятого уровня значимости Табличное значение
критерия Фишера определяется дл числа степеней свободы u-1 и N-1 и
вероятности ошибки Т.е если Если Результаты дисперсионного анализа сводятся в таблицу 2. Таблица 2 Однофакторный дисперсионный анализ
2.1.2. Двухфакторный дисперсионный анализ при перекрестной классификации факторов Часто необходимо качественно оценить значимость или незначимость влияния на целевую функцию u двух одновременно действующих факторов x1 и x2 . Такими факторами могут быть, например, форма собственности предприятия x1 и вид экономической деятельности x2. Модель двухфакторного дисперсионного анализа имеет вид [1-4]:
где В этом случае общую сумму квадратов отклонений Q0 можно разбить на четыре суммы: 1) Qx1-по фактору x1, 2) Qx2-по фактору x2, 3) Qe-остаточную сумму квадратов, зависящую от ошибки e, 4) Q x1x2-зависящую от взаимодействия (произведения) x1x2 двух факторов. В этом случае по выборочным значениям вычисляются: 1) среднее
2) среднее
3) общее среднее
4) среднее
В табл.2 показаны данные полного факторного эксперимента с одинаковым числом наблюдений в ячейках. Таблица 3. - Данные эксперимента и расчёты средних при двухфакторном дисперсионном анализе
В табл.2 Общая сумма квадратов отклонений Q0 рассчитывается по формуле:
Эту сумму можно разложить на 4 составляющие: 1) сумму, характеризующую влияние фактора x1:
2) сумму, характеризующую влияние фактора x2:
3) сумму, характеризующую результат влияния взаимодействия x1x2:
4) сумму, характеризующую влияние ошибки e:
Указанные пять сумм, поделенные на соответствующее число степеней свободы, дают пять различных оценок дисперсии, если влияние факторов x1 и x2 незначимо. Для проведения дисперсионного анализа вычисляются следующие дисперсии: 1) оценка дисперсии относительно общего среднего
где
2) оценка дисперсии «между строками», определяемыми уровнями x1j:
где 3) оценка дисперсии «между столбцами», соответствующими уровням фактора x2:
где 4) оценка дисперсии «между сериями» по m параллельным опытам каждая
с числом степеней свободы
5) оценка дисперсии «внутри серий» по m параллельным опытам, вычисляемая как средняя оценка по всем u1u2 сериям:
с числом степеней свободы
Числа степеней свободы должны удовлетворять соотношению
Статистическое оценивание значимости влияния факторов x1 , x2 и взаимодействия x1x2 выполняются по F-критерию Фишера, для чего формируются следующие F-отношения:
Фактор x1 или
x2 , или взаимодействие x1x2 признаются
незначимым, если соответствующее F-отношение оказывается меньше критического,
выбранного из таблиц для принятого уровня значимости Для того, чтобы сделать вывод о том, влияют ли на исследуемые показатели качественные факторы, выдвигают следующие гипотезы: H0: H1: H0: H1: H0: H1: Если Если Результаты двухфакторного дисперсионного анализа представляются в виде табл.3. Таблица 3. - Двухфакторный дисперсионный анализ при равном числе наблюдений в ячейках
m – число данных в строке (число
повторов в ячейке), 3. Дисперсионный анализ в системе MINITAB Для проведения дисперсионного анализа в системе MINITAB необходимо выбрать из меню Stat > ANOVA. Различные возможности проведения дисперсионного анализа представлены следующими командами. Команда Oneway позволяет провести однофакторный дисперсионный анализ, если значения выходного и влияющего параметра записаны в двух столбцах. Команда Oneway(Unstacked) позволяет провести однофакторный дисперсионный анализ, если значения выходного параметра разбито на группы и значения для каждой группы записаны в разных столбцах. Команда Twoway позволяет провести двухфакторный анализ для сбалансированных данных (с одинаковым количеством значений в каждой ячейке). Команда Balanced ANOVA позволяет провести многофакторный дисперсионный анализ для сбалансированных моделей с перекрестной и иерархической классификацией. Команда General Linear Model позволяет провести многофакторный несбалансированный дисперсионный анализ для моделей с перекрестной и иерархической классификацией. 3.2.1. Однофакторный дисперсионный анализДля проведения однофакторного дисперсионного анализа необходимо подготовить данные в двух столбцах (в первом – входная переменная, качественная, во втором – выходная переменная), выбрать из меню Stat > ANOVA > Oneway и заполнить открывшееся диалоговое окно. Диалоговое окно. 1. Отклик (Response) – выберите столбец, содержащий выходную (зависимую) переменную. Столбец должен содержать только числовые значения. 2. Фактор (Factor) – выберите столбец, содержащий качественную переменную, влияние которой исследуется. Фактор может иметь как числовые, так и символьные значения. 3. Сохранить остатки (Store Residuals), выбирается, если необходимо сохранить остатки для последующего анализа. Остатки сохраняются в свободном столбце. 4. Сохранить оценки (Store fits) Для однофакторного анализа оценки это средние значения для каждого уровня фактора. 5. Графики <Graphs> представляют данные в виде точечных и блочных диаграмм для каждой группы с отмеченным средним значением. Пример 1Пусть данные о проценте износа оборудования для 12 предприятий разных отраслей промышленности и форм собственности представлены следующей таблицей. Таблица 4. Исходные данные
Определим зависимость износа оборудования от отрасли промышленности. В этом случае в диалоговом окне указываются следующие значения Response: d Factor: field Результаты дисперсионного анализа включают таблицу анализа дисперсии, таблицу средних значений уровней факторов, индивидуальные доверительные интервалы для каждого уровня и общее стандартное отклонение. На рис.1 представлен листинг результатов вычислений. На рисунке используются следующие обозначения: DF – число степеней свободы, SS - сумма квадратов, MS – средний квадрат, F - отношение Фишера, P - уровень значимости для вычисленного F, Level – уровень фактора, Mean – среднее значение, StDev – стандартное отклонение. One-Way Analysis of Variance Analysis of Variance for d Source DF SS MS F P field 1 102.1 102.1 1.55 0.241 Error 10 656.8 65.7 Total 11 758.9 Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev -------+---------+---------+--------- Пищевая 6 45.667 9.852 (-----------*-----------) Машиност 6 51.500 5.857 (-----------*-----------) -------+---------+---------+--------- Pooled StDev = 8.105 42.0 48.0 54.0 Рис.1 Листинг результатов вычислений для однофакторной модели Если значения выходной переменной разбито на группы и каждая группа записана в отдельном столбце, то для проведения однофакторного дисперсионного анализа необходимо выбрать из меню Stat > ANOVA > Oneway [Unstacked] и заполнить следующее диалоговое окно. Диалоговое окно 1. Отклик в нескольких столбцах Responses [in separate columns] - выберите столбцы, содержащие выходную (зависимую) переменную. Столбцы должны содержать только числовые значения. Система не требует, чтобы в каждом столбце было одинаковое число наблюдений. 2. Графики <Graphs> представляют данные в виде точечных и блочных диаграмм для каждой группы с отмеченным средним значением. Пример 2Пусть данные о проценте износа оборудования для 12 предприятий двух отраслей промышленности (пищевая - field1, машиностроение - field2) представлены в табл.5. Таблица 5. Исходные данные
В этом случае в диалоговом окне указываются следующие значения. Responses [in separate columns]: field1 field2 Результатом дисперсионного анализа будет таблица представленная на рис.2. One-Way Analysis of Variance Analysis of Variance Source DF SS MS F P Factor 1 182.7 182.7 3.17 0.105 Error 10 576.2 57.6 Total 11 758.9 Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev ------+---------+---------+---------+ field1 7 45.286 9.050 (---------*----------) field2 5 53.200 4.604 (------------*-----------) ------+---------+---------+---------+ Pooled StDev = 7.591 42.0 48.0 54.0 60.0 Рис.2 Листинг результатов вычислений Из полученных результатов
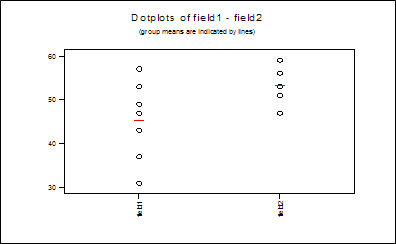
видно, что P> Если в опции <Graphs> указать Dotplots of data:Ö, то будет построен следующий график (чертой отмечено среднее значение для группы).
Рис.3 Представление экспериментальных данных 3.2.2. Двухфакторный дисперсионный анализДля проведения двухфакторного дисперсионного анализа необходимо подготовить данные, выбрать из меню Stat > ANOVA > Balanced ANOVA и заполнить открывшееся диалоговое окно. Эта функция позволяет проводить, как одномерный, так и многомерный анализ дисперсии. Факторы могут быть связаны как перекрестно, так и иерархически, они могут быть детерминированными и случайными, однако данные должны быть сбалансированы. Это значит, что для каждого уровня A должны быть одинаковые уровни фактора B, и в том же количестве. Диалоговое окно. 1. Отклики (Responses) – выберите столбцы, содержащие выходные (зависимые) переменные. Система позволяет анализировать до 50 выходных переменных. 2. Модель (Model) – укажите переменные или их комбинацию, которые включаются в модель. 3. Случайные факторы (Random Factors) – укажите столбец, содержащий случайную переменную. Пример 3Пусть данные о проценте износа оборудования для 12 предприятий разных отраслей промышленности и форм собственности представлены в табл.1. Определим, как влияют отрасль промышленности, форма собственности и их взаимодействие на процент износа оборудование. Для этого выберем из меню Stat > ANOVA > Balanced ANOVA и заполним диалоговое окно следующим образом Responses: d Model: field owner field*owner Результаты дисперсионного анализа представлены на рис.4. Analysis of Variance (Balanced Designs) Factor Type Levels Values field fixed 2 Пищевая Машиностр owner fixed 2 частн госуд Analysis of Variance for d Source DF SS MS F P field 1 102.08 102.08 2.14 0.182 owner 1 184.08 184.08 3.86 0.085 field*owner 1 90.75 90.75 1.90 0.205 Error 8 382.00 47.75 Total 11 758.92 Рис.4 Листинг результатов вычислений для двухфакторной моделиПроанализируем полученные результатs/ Для фактора отрасли P> Для фактора формы
собственности P> Для анализа многофакторных моделей по несбалансированным данным необходимо выбрать из меню Stat > ANOVA > General Linear Model. 4 Выполнение дисперсионного анализа в Excel Рассмотрим дисперсионный анализ на следующем примере: за месяц известны данные о выработке рабочего за время работы в первую и во вторую смены. Таблица 2 - Исходные данные
Можно ли считать, что расхождение между уровнями выработки рабочего в первую и во вторую смены несущественно, т.е. можно ли считать, что генеральные средние в двух подгруппах одинаковы и, следовательно, выработка рабочего может быть охарактеризована общей средней. Решение. Для того чтобы ответить на поставленные вопросы, рассчитаем среднюю выработку рабочих в каждой смене. Величина выработки в первую и вторую смены различна. Теперь возникает вопрос о том, насколько существенны эти расхождения, нужно проверить предположение о возможном влиянии сменности на выработку рабочих. Результаты расчетов сведены в таблицу 3. Таблица 3 – Промежуточные расчеты для проведения дисперсионного анализа
Используя данные таблицы,
рассчитаем Число степеней свободы
для расчета внутригрупповой дисперсии равно (
Рассчитаем значение критерия Фишера по следующей формуле:
В соответствии с числом степеней свободы для расчета внутригрупповой и межгрупповой дисперсий (24 и 1) в таблице F-распределения для α=5% находим Fтабл = 4.26. При этом выдвигается две гипотезы. Нулевая гипотеза гласит о том, что различия выработки рабочего в первую и вторую смены несущественны. Альтернативная гипотеза: существуют существенные различия в значении выработки рабочего в первую и во вторую смены. Так как расчетное значение критерия Фишера значительно меньше табличного значения критерия Фишера, то гипотеза о несущественности различия выработки рабочего в первую и вторую смены не опровергается, т.е. сменность не оказывает влияния на уровень выработки рабочего. Для того, чтобы провести дисперсионный анализ в Excel, необходимо активировать команду «Анализ данных». Для этого проходится следующий путь: Сервис -> Надстройки -> Пакет анализа. После этого в меню «Сервис» появляется команда «Анализ данных» и выбирается команда «Однофакторный дисперсионный анализ». Далее необходимо заполнить окно «Однофакторный дисперсионный анализ»: Страницы: 1, 2 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

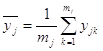 ;
;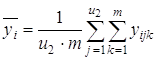 ;
;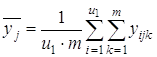 ;
;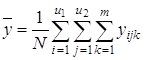 ;
;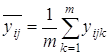 .
.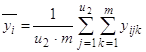
 i =
i =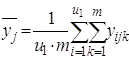
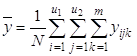
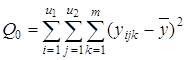
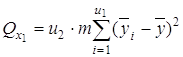 ;
;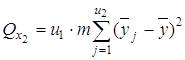 ;
;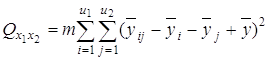
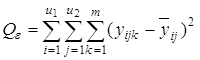
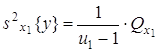 ,
,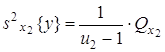 ,
,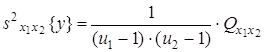
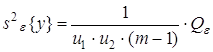
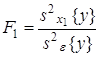 ,
, 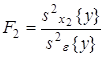 ,
, 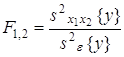 .
.